Supervised Learning Performance Measurement: Regression Models

Introduction
Let's quickly review the two categories of supervised learning models: regression models and classification models. Regression models predict a continuous dependent variable, such as an integer result. On the other hand, classification models predict a class result, like whether a student will pass an exam or not. For this article, we will focus on regression models.
Relevance of Performances Measurements
Once we have created our model, it is important to assess its performance in a real-world setting. This involves checking for overfitting or underfitting and determining the level of accuracy we can expect. Performance measurements are used to evaluate our models and their reliability. There are several metrics available to measure regression model performance, such as MSE, RMSE, MAE, R-squared, and Adjusted R-squared. In this article, we will focus on these commonly used metrics.
Common Performance Metrics
MSE - Mean Squared Error
The mean square error gives us an average of the variance of our model.
It is calculated using the formula:

Ỹ - the predicted value of our model
Y - the actual value of our model
n - the number of data points (row)
Implementation in Python
def mean_squared_error(predictions, targets):
if len(predictions) != len(targets):
raise ValueError("Input lists must have the same length")
squared_errors = [(p - t) ** 2 for p, t in zip(predictions, targets)]
mse = sum(squared_errors) / len(predictions)
return mse
predicted_values = [2.5, 3.7, 4.8, 6.1, 7.3]
actual_values = [2.1, 3.8, 5.0, 5.9, 7.2]
mse = mean_squared_error(predicted_values, actual_values)
print("Mean Squared Error:", mse)
RMSE - Root Mean Squared Error
Our RMSE Metric builds on the aforementioned MSE metric. With the addition of taking the square root of the MSE (to return the value to the original unit before it was squared in MSE)
It is calculated with this formula:

Implementation in Python
import math
def root_mean_squared_error(predictions, targets):
if len(predictions) != len(targets):
raise ValueError("Input lists must have the same length")
squared_errors = [(p - t) ** 2 for p, t in zip(predictions, targets)]
mean_squared_error = sum(squared_errors) / len(predictions)
rmse = math.sqrt(mean_squared_error)
return rmse
predicted_values = [2.5, 3.7, 4.8, 6.1, 7.3]
actual_values = [2.1, 3.8, 5.0, 5.9, 7.2]
rmse = root_mean_squared_error(predicted_values, actual_values)
print("Root Mean Squared Error:", rmse)
MAE - Mean Absolute Error
Similar to the MSE metric, instead of calculating the square of the difference between the actual and predicted, we take the absolute difference.

Implementation in Python
def mean_absolute_error(predictions, targets):
if len(predictions) != len(targets):
raise ValueError("Input lists must have the same length")
absolute_errors = [abs(p - t) for p, t in zip(predictions, targets)]
mae = sum(absolute_errors) / len(predictions)
return mae
predicted_values = [2.5, 3.7, 4.8, 6.1, 7.3]
actual_values = [2.1, 3.8, 5.0, 5.9, 7.2]
mae = mean_absolute_error(predicted_values, actual_values)
print("Mean Absolute Error:", mae)
R-squared
R-squared (Coefficient of Determination) is a statistical measure that represents the proportion of the variance for the dependent variable (target) that's explained by independent variables (predictors) in a regression model. It provides an indication of the goodness of fit of a regression model to the observed data points. In other words, R-squared tells you how well the regression line fits the data points.
The R-squared value ranges from 0 to 1. Here's what it indicates:
R-squared = 0: The model explains none of the variance in the dependent variable. It doesn't fit the data at all.
R-squared = 1: The model explains 100% of the variance in the dependent variable. It perfectly fits the data.
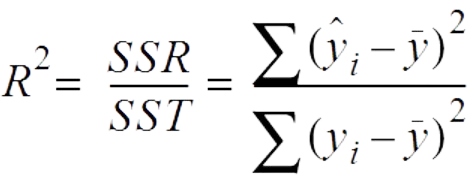
Implementation in Python
from sklearn.linear_model import LinearRegression
from sklearn.metrics import r2_score
# Example data
X = [[1], [2], [3], [4], [5]]
y = [2, 3.9, 6.1, 8.0, 9.8]
# Create and fit a linear regression model
model = LinearRegression()
model.fit(X, y)
# Predict the target values
y_pred = model.predict(X)
# Calculate R-squared
r_squared = r2_score(y, y_pred)
print("R-squared:", r_squared)
Adjusted R-squared
Adjusted R-squared is a modified version of the regular R-squared (Coefficient of Determination) that takes into account the number of predictor variables in a regression model. While R-squared measures the proportion of the variance in the dependent variable explained by the independent variables, Adjusted R-squared adjusts this value based on the number of predictors and the sample size.
The idea behind Adjusted R-squared is to penalize the inclusion of unnecessary variables that might artificially inflate the R-squared value. As more predictor variables are added to a model, the R-squared value tends to increase even if those variables don't contribute significantly to the model's predictive power. Adjusted R-squared provides a more balanced assessment of a model's goodness of fit, especially when comparing models with different numbers of predictors.
Mathematically, the Adjusted R-squared is calculated using the following formula:
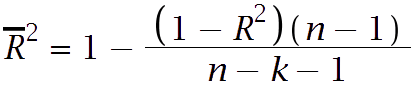
Where:
( R^2 ) is the regular R-squared value.
( n ) is the number of observations (sample size).
( k ) is the number of predictor variables in the model.
Adjusted R-squared will always be lower than or equal to the regular R-squared. If the model adds meaningful explanatory power, the Adjusted R-squared will increase; if it adds little or no explanatory power (or if it overfits), the Adjusted R-squared will decrease or stay the same.
Implementation in Python
import numpy as np
import statsmodels.api as sm
# Example data
X = np.array([[1, 2], [2, 3], [3, 4], [4, 5], [5, 6]])
y = np.array([3, 6, 8, 10, 12])
# Add a constant term to the predictor matrix
X = sm.add_constant(X)
# Create and fit a linear regression model
model = sm.OLS(y, X).fit()
# Calculate Adjusted R-squared
adjusted_r_squared = 1 - (1 - model.rsquared) * (len(y) - 1) / (len(y) - X.shape[1] - 1)
print("Adjusted R-squared:", adjusted_r_squared)
Conclusion
It is important to measure performance in order to determine the quality of our model and identify areas for improvement. The metrics mentioned above are particularly relevant when working with linear regression models.